Adversarial Machine Learning Attacks

Machine learning powers everything from spam filters in your email to self-driving cars on the road. But what happens when bad actors try to mess with these systems? That’s where adversarial machine learning attacks come in. These are clever ways hackers can trick or break machine learning models, and one of the sneakiest types is poisoning the data that trains them. If you’re curious about how attackers pull this off and what you can do to stop them, stick around. We’ll break it down step by step, from the basics to real-world fixes.
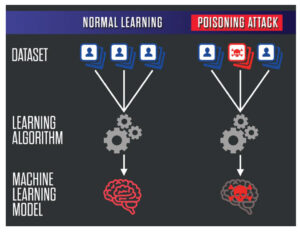
Machine learning isn’t some magic box—it’s software that learns patterns from data to make decisions. But if that data gets tampered with, the whole system can go haywire. Poisoning attacks happen during training, where attackers slip in fake or altered data to make the model behave badly later on. Think of it like adding bad ingredients to a recipe; the final dish comes out wrong every time.
Why should you care? These attacks can lead to serious problems, like faulty medical diagnoses or hacked security systems. According to experts, as AI gets more common, these threats are only growing. In this post, we’ll explore how these attacks work, especially focusing on poisoning methods, and share practical ways to defend your models.
What Is Machine Learning and Why Is It Vulnerable?
Before we get into the attacks, let’s make sure we’re on the same page about machine learning. At its core, machine learning is a way for computers to learn from examples without being explicitly programmed for every scenario. You feed it a bunch of data—say, thousands of emails labeled as “spam” or “not spam”—and it figures out patterns to classify new ones.
There are different types: supervised learning uses labeled data, unsupervised finds patterns on its own, and reinforcement learning learns through trial and error. Tools like Python’s scikit-learn or TensorFlow make it accessible for developers.
But here’s the catch—machine learning models assume the data they’re trained on is trustworthy. In reality, data comes from all over: user inputs, sensors, or web scrapes. If an attacker gets access, they can inject junk that skews the learning process. This vulnerability stems from how models generalize; they’re great at patterns but bad at spotting sneaky changes.
For more on the fundamentals, check out our guide on machine learning basics to see how these systems are built from the ground up.
Diving Into Adversarial Machine Learning Attacks
Adversarial machine learning attacks are deliberate attempts to fool AI systems. They’re not random bugs; they’re targeted exploits. The term “adversarial” comes from game theory, where one player (the attacker) tries to outsmart another (the model).
These attacks fall into a few categories:
- Evasion Attacks: These happen at test time. An attacker tweaks input data slightly to trick a trained model. For example, adding noise to an image so a self-driving car misreads a stop sign as a speed limit.

Image credit: PyImageSearch
- Extraction Attacks: Stealing the model’s inner workings, like copying a proprietary algorithm.
- Inference Attacks: Guessing private data from model outputs, raising privacy concerns.
But our main focus here is on poisoning attacks, a subset of adversarial machine learning attacks that hit during training.
Poisoning is especially dangerous because it’s hard to detect early. Once the model is trained on bad data, it’s baked in. Attackers might control a small portion of the training set—say, 1-5%—and that’s often enough to cause trouble.
How Do Poisoning Attacks Work in Adversarial Machine Learning?
Poisoning attacks are like planting a time bomb in the model’s foundation. The attacker adds malicious data points to the training set, which alters how the model learns. When deployed, it makes wrong predictions on purpose.
Let’s break down the mechanics.
The Basics of Data Poisoning
In a typical setup, a model trains on a dataset D with features (inputs) and labels (outputs). An attacker creates poisoned samples D’ and mixes them into D. The goal? Shift the model’s decision boundary—the invisible line it uses to classify things.
For instance, in a spam filter, an attacker could inject emails labeled as “not spam” that look like spam. Over time, the model learns to ignore real spam.
There are two main flavors:
- Availability Poisoning: Makes the whole model less accurate. The attacker wants widespread failures, like reducing a classifier’s accuracy from 95% to 70%.
- Targeted Poisoning: Affects specific inputs. For example, making the model misclassify a particular user’s data while working fine otherwise.
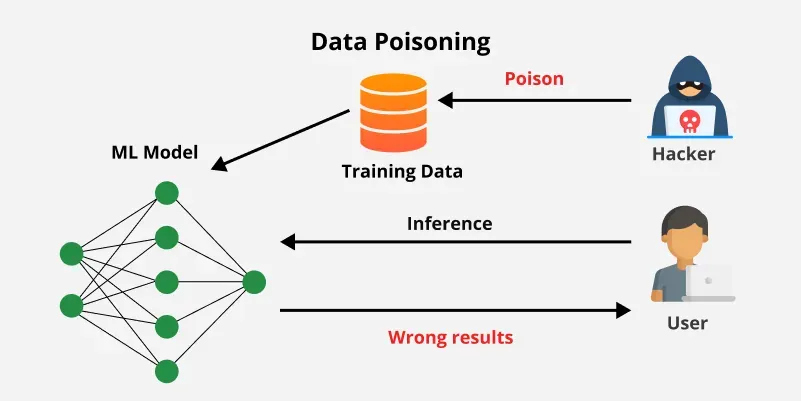
Image credit: GeeksforGeeks
Types of Poisoning Attacks
Poisoning isn’t one-size-fits-all. Here are common methods:
- Label-Flipping Attacks: The simplest. Flip labels on existing data. A “cat” image becomes “dog.” If enough are flipped, the model confuses the two.
- Clean-Label Poisoning: Trickier because labels stay correct, but features are tweaked subtly. The model still learns wrong associations. Research shows this works even with black-box access, where the attacker doesn’t know the model’s details.
- Backdoor Poisoning: Plants a “trigger” in the data, like a specific pixel pattern in images. When the trigger appears at test time, the model outputs what the attacker wants. Otherwise, it behaves normally. This is stealthy and hard to spot.
- Model Poisoning in Federated Learning: In distributed systems like federated learning (where models train on decentralized data), attackers poison local updates that get aggregated. This affects the global model.

Image credit: Information Matters
Attackers use optimization techniques, like gradient ascent, to craft these poisons efficiently. They might solve math problems to find the minimal changes needed for maximum impact.
Real-World Examples of Poisoning Attacks
These aren’t just theory. In 2018, researchers showed how poisoning could fool facial recognition systems. By adding altered images to training, they made the model misidentify people.
Another case: In cybersecurity, attackers poison intrusion detection systems. They inject benign-looking malicious traffic during training, so the system ignores real threats later.
In healthcare, imagine poisoning a diagnostic AI with fake X-rays. It could lead to wrong diagnoses, endangering lives.
Even big companies aren’t immune. Microsoft’s Tay chatbot was “poisoned” by users feeding it bad data in real-time, turning it racist overnight. While not traditional ML poisoning, it shows the risks of open training.
For a deeper look, read this NIST report on adversarial attacks taxonomy, which details various methods.
The Impact of Adversarial Machine Learning Attacks
The consequences can be huge. In finance, a poisoned fraud detection model might let through millions in scams. In autonomous vehicles, it could cause accidents.
Privacy is another issue. Some attacks extract sensitive data from models, like membership inference where attackers guess if your data was in the training set.
Economically, fixing a poisoned model means retraining from scratch, costing time and money. Plus, loss of trust—users might abandon AI systems if they’re seen as unreliable.
On the bright side, awareness is growing. Governments are pushing for AI safety standards, and companies like Google invest in robust ML.
Link to our post on AI ethics and security for more on the broader implications.
How to Defend Against Poisoning in Adversarial Machine Learning Attacks
Good news: There are ways to fight back. Defenses focus on making models robust, detecting poisons, and securing the pipeline.
Core Defense Strategies
- Data Sanitization: Before training, clean the data. Use anomaly detection to spot outliers. Techniques like clustering group similar data; anything odd gets removed.For example, in Python, you can use Isolation Forest from scikit-learn to flag suspicious samples.
- Adversarial Training: Train the model on both clean and adversarial examples. It learns to handle perturbations. This boosts robustness but can slow training and reduce accuracy on clean data.

Image credit: Nature.com
- Ensemble Methods: Use multiple models instead of one. If one gets poisoned, others can vote on the output. Risk-based ensembles route data smartly to avoid concentrating poisons.
- Differential Privacy: Add noise to data or gradients during training. This masks individual contributions, making poisoning harder without hurting overall learning.
- Anomaly Detection in Training: Monitor metrics like loss during training. Spikes might indicate poison. Tools like TensorBoard help visualize this.
- Federated Learning Defenses: In distributed setups, use robust aggregation methods like Krum, which discards suspicious updates.
Advanced Techniques
- Influence Functions: Calculate how much each data point affects the model. Remove high-influence ones if they’re suspect.
- Certified Defenses: Math proofs that guarantee robustness against certain attack strengths. Useful for critical apps.
- Monitoring and Auditing: Post-training, test with known adversarial sets. Libraries like CleverHans provide attack simulations.
For implementation, check out Palo Alto Networks’ guide on adversarial attacks.
Best Practices for Developers
- Secure Data Sources: Vet where data comes from. Use verified datasets like those from Kaggle or UCI.
- Version Control: Track data changes with tools like DVC.
- Regular Audits: Retrain periodically with fresh data.
- Hybrid Approaches: Combine defenses for better coverage.
In our cybersecurity in AI article, we discuss integrating these into workflows.

Challenges and Future Directions
Defenses aren’t perfect. Attackers adapt, creating “adaptive attacks” that bypass known fixes. There’s a cat-and-mouse game between attackers and defenders.
Open challenges include scaling defenses for huge datasets and handling real-time learning.
Looking ahead, research focuses on explainable AI to spot poisons easier. Quantum computing might help or hinder—it’s early days.
For the latest, follow arXiv papers on adversarial ML.
Wrapping Up: Staying Ahead of Adversarial Machine Learning Attacks
Adversarial machine learning attacks, especially poisoning, pose real risks to AI reliability. By understanding how attackers poison models—through label flips, backdoors, or clean-label tricks—you can better protect your systems. Defenses like data cleaning, adversarial training, and ensembles go a long way.
Remember, security is ongoing. Keep learning, test rigorously, and collaborate. If you’re building ML apps, start with robust practices today.
What are your thoughts on these attacks? Share in the comments. For more tech insights, explore our AI security series.
Share this content:







Post Comment